賈文輝等基于機器學(xué)習算法構(gòu)建了腦梗死后出血轉(zhuǎn)化預(yù)測模型及進行相關(guān)危險因素研究
腦梗死后出血轉(zhuǎn)化(HT)是腦梗死最危險的并發(fā)癥���。HT是導(dǎo)致臨床醫(yī)療事故糾紛常見原因���,同時因為臨床醫(yī)師和患者擔心出血轉(zhuǎn)化導(dǎo)致我國靜脈溶栓率低、房顫抗凝藥物使用率低����、抗栓藥物使用率低�、患者不當停藥等�����,嚴重阻礙腦梗死有效防治��。所以能夠早期發(fā)現(xiàn)識別HT危險預(yù)測因素�����,建立一種準確高效簡易的預(yù)測量表模型將是我們防治腦梗死出血轉(zhuǎn)化并發(fā)癥��,進行預(yù)防的有力工具�。國外已經(jīng)開發(fā)了一些HT預(yù)測模型,如溶血后出血評分(HAT評分)�����、溶栓后癥狀性腦出血評分模型(SITS-MOST評分)�����、 GRASPS癥狀性顱內(nèi)出血預(yù)測評分�����、iScore預(yù)測模型等�����,以上各預(yù)測模型雖然各有優(yōu)點���,但都存在缺乏影像學(xué)資料����、影像學(xué)新技術(shù)和血清標志物而預(yù)測效能差的問題�,有必要建立一種全面準確的HT預(yù)測模型。
賈文輝等在臨床研究中����,針對數(shù)據(jù)處理和模型構(gòu)建方面��,患者信息呈現(xiàn)幾何數(shù)量級增長����、海量大數(shù)據(jù)的特點��,腦梗死相關(guān)危險因素往往是信息量大��、復(fù)雜多變��,傳統(tǒng)數(shù)據(jù)處理方法弊端顯現(xiàn)��,其無法解決數(shù)據(jù)之間非線性的問題�,很難去擬合數(shù)據(jù)的真實分布��,特別是數(shù)據(jù)量大���、變量多、變量之間關(guān)系復(fù)雜呈共線等的情況下傳統(tǒng)模型處理低效效能差,采用機器學(xué)習算法��,為開展海量信息的挖掘分析,提供了有效的解決途徑。機器學(xué)習并不需要事先對大量數(shù)據(jù)進行人工分析,然后提取規(guī)則并建立模型,而是提供了一種更為有效的方法來捕捉數(shù)據(jù)中的知識�����,逐步提高預(yù)測模型的性能,以完成數(shù)據(jù)驅(qū)動的決策�����。
機器學(xué)習模型中��,LR是機器學(xué)習中的一種基于概率的分類算法,屬于監(jiān)督學(xué)習技術(shù)����,是一種使用邏輯函數(shù)對條件概率進行建模的統(tǒng)計模型�。RF是集成學(xué)習Bagging算法當中的典型代表����,它使用了CART決策樹作為基學(xué)習器,結(jié)合自助采樣法從總體樣本當中隨機取一部分樣本進行訓(xùn)練����,通過多次這樣的抽取來并行化訓(xùn)練許多棵決策樹���,并將多棵決策樹的預(yù)測結(jié)果整合起來使用�,這樣使得最終集成模型具有很強的泛化能力�,并且能夠降低模型的方差�����。AdaBoost算法屬于集成學(xué)習Boosting算法中的一種���,模型的訓(xùn)練過程是不斷迭代提升的����,每一個基分類器都是根據(jù)前一個基分類器的預(yù)測結(jié)果����,增加分類錯誤樣本集合的權(quán)重,減小分類正確樣本集合的權(quán)重�����,以此來提升模型的泛化能力����。XGBoost算法是集成學(xué)習Boosting算法中的一種��,它是通過新加入的基分類器進一步擬合預(yù)測值與真實值之間的差異�,同時XGBoost在損失函數(shù)中加入正則化項����,并對損失函數(shù)進行二階泰勒展開�,以減少過擬合的可能�����,并加快模型的收斂速度。SVM是由Cortes和Vapkin 在統(tǒng)計學(xué)習理論的基礎(chǔ)上提出的一種機器學(xué)習方法[6]�。它的基本思想是找到一個能夠滿足分類要求的最大間隔超平面�,并且在保證分類精度的情況下,最大化該分類面兩側(cè)的空白區(qū)域�����。SVM能夠執(zhí)行線性或非線性分類、回歸����,甚至是異常值檢測任務(wù)��,在醫(yī)療診斷�����、圖像識別、文本分類等有著非常廣泛的應(yīng)用�。
在機器學(xué)習中���,采用混淆矩陣(Confusion Matrix)作為分類問題的性能評價指標����,混淆矩陣又稱為可能性矩陣���,在無監(jiān)督學(xué)習中一般叫做匹配矩陣�,通過混淆矩陣,能夠直觀地看出模型對每個類別的預(yù)測情況��。常用的指標有精確度�、準確度、特異度�、靈敏度、約登指數(shù)���。(模型技術(shù)路線圖見圖1)����。
圖1 預(yù)測模型技術(shù)路線圖

在研究中對腦梗死后出血轉(zhuǎn)化的66個變量進行單因素比較后���,將28項代入機器學(xué)習算法預(yù)測模型進行篩選變量和模型評價�����,結(jié)果如下:
研究結(jié)果1 LR模型篩選結(jié)果
將篩選出來的28個變量作為特征,是否發(fā)生腦梗死出血轉(zhuǎn)化作為標簽輸入到LR模型��。從Scikit-Learn庫導(dǎo)入Logistic Regression模塊構(gòu)建LR模型����,在訓(xùn)練集上對模型進行訓(xùn)練�,在測試集上對訓(xùn)練好的模型進行性能評估�。此外LR對HT風險因素進行篩選重要度排序,排名前10的是:NIHSS評分���、入院舒張壓��、白蛋白�����、血紅蛋白Hb���、中心粒與淋巴細胞比值NLR、PT�、雙抗治療、空腹血糖�����、腦微出血CMB��、腦白質(zhì)病變����。模型預(yù)測結(jié)果為:精確度為0.73�,準確度為0.70�,靈敏度為0.80,特異度為0.67�����,約登指數(shù)為0.45���,AUC為0.83����。具體指標見下表1���、圖2����。
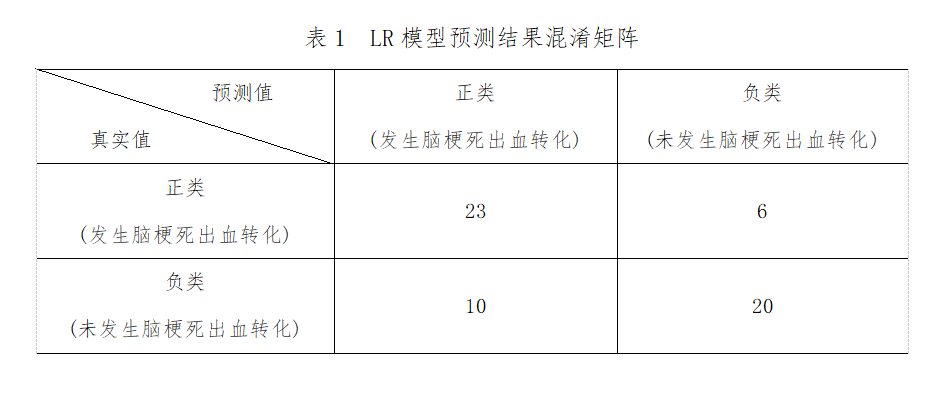
圖2 LR模型分析結(jié)果

研究結(jié)果2 RF模型篩選結(jié)果
將篩選出來的28個變量作為特征�,是否發(fā)生HT作為標簽輸入到RF模型。從Scikit-Learn庫導(dǎo)入Random Forest Classifier模塊構(gòu)建RF模型��,在訓(xùn)練集上對模型進行訓(xùn)練�,同時調(diào)用Grid SearchCV函數(shù)探索模型的最優(yōu)超參數(shù)組合��,采用5折交叉驗證的方式,以“rocauc”作為模型評價標準�����,保存最優(yōu)模型并在測試集上對模型進行評估�。最優(yōu)超參數(shù)組合:max_features=20,nestimators=100���。此外���,RF對腦梗死出血轉(zhuǎn)化風險因素進行重要度篩選排序,排名前10的是:肌鈣蛋白�、BNP、白蛋白�、CMB、NIHSS�、大面積腦梗死LHI、NLR���、D-二聚體���、雙抗治療、尿酸。模型預(yù)測結(jié)果為:精確度為0.97�,準確度為0.97,靈敏度為0.97��,特異度為0.97���,約登指數(shù)為0.93�����,AUC為0.97��。具體指標見下表2��、圖3�。
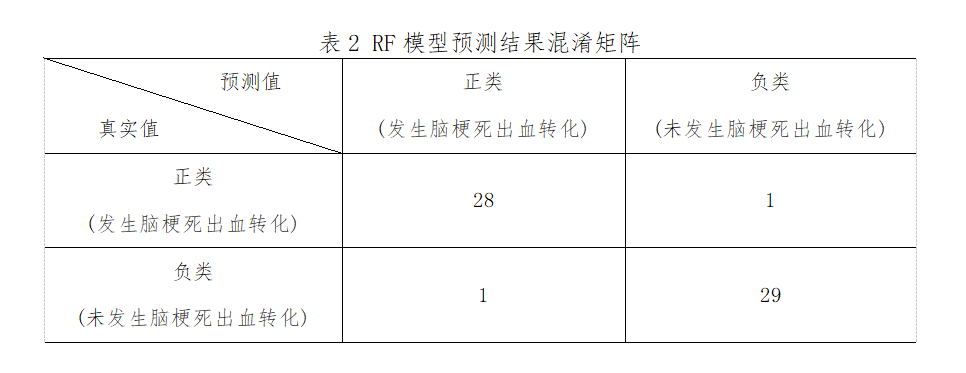
圖3 RF模型分析結(jié)果

研究結(jié)果3 AdaBoos模型篩選結(jié)果
將篩選出來的28個變量作為特征����,是否發(fā)生腦梗死出血轉(zhuǎn)化作為標簽輸入到AdaBoost模型。從Scikit-Learn庫導(dǎo)入AdaBoost Classifier模塊構(gòu)建AdaBoost模型�,在訓(xùn)練集上對模型進行訓(xùn)練,同時調(diào)用GridSearchCV函數(shù)探索模型的最優(yōu)超參數(shù)組合��,采用5折交叉驗證的方式�����,以“rocauc”作為模型評價標準���,保存最優(yōu)模型并在測試集上對模型進行評估���。最優(yōu)超參數(shù)組合:learning_rate=0.4,nestimators=300�����。此外�����,AdaBoost對HT風險因素進行重要度排序�,排名前的是:肌鈣蛋白、BNP����、血糖、白蛋白��、NLR��、尿酸、腦白質(zhì)病變WMH���、雙抗治療����、年齡����、NIHSS。模型預(yù)測結(jié)果為:精確度為0.97��,準確度為0.97���,靈敏度為0.97��,特異度為0.97��,約登指數(shù)為0.93����,AUC為0.99���。具體指標見下表3�、圖4。
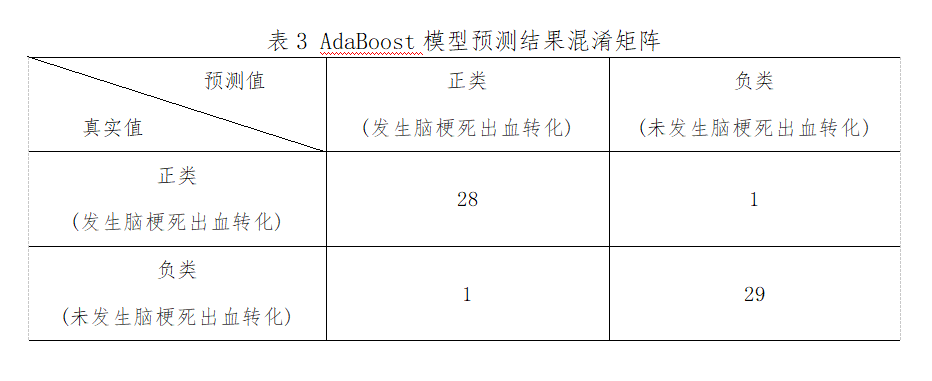
圖4 AdaBoost模型預(yù)測結(jié)果

研究結(jié)果4 XGBoost模型篩選結(jié)果
將篩選出來的28個變量作為特征�����,是否發(fā)生腦梗死出血轉(zhuǎn)化作為標簽輸入到XGBoost模型����。從Scikit-Learn庫導(dǎo)入XGBClassifier模塊構(gòu)建XGBoost模型�,在訓(xùn)練集上對模型進行訓(xùn)練,同時����,調(diào)用GridSearchCV函數(shù)探索模型的最優(yōu)超參數(shù)組合,采用5折交叉驗證的方式���,以“roc_auc”作為模型評價標準����,保存最優(yōu)模型并在測試集上對模型進行評估�����。最優(yōu)超參數(shù)組合:colsample_bytree=0.6,learning_rate=0.01,max_depth=2,min_child_weight=1, nestimators=100, subsample=0.9���。此外,XGBoost對腦梗死出血轉(zhuǎn)化風險因素進行重要度排序�,排名前10的是:肌鈣蛋白、BNP�����、CMB�、LHI、靜脈溶栓、NIHSS�、雙抗治療、NLR�、D-二聚體、尿酸���。模型預(yù)測結(jié)果為:精確度為0.98���,準確度為0.97,靈敏度為1.00���,特異度為0.97��,約登指數(shù)為0.97�,AUC為0.99���。具體指標見下表4��、圖5。
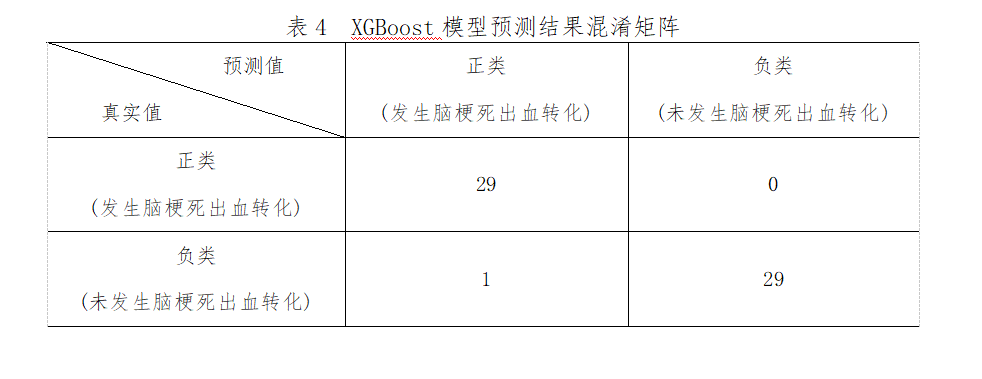
圖5 XGBoost模型預(yù)測結(jié)果

研究結(jié)果5 SVM模型篩選結(jié)果
將篩選出來的28個變量作為特征����,是否發(fā)生腦梗死出血轉(zhuǎn)化作為標簽輸入到SVM模型。從Scikit-Learn庫導(dǎo)入svm模塊構(gòu)建SVM模型,選取核函數(shù)為線性核函數(shù)���,在訓(xùn)練集上對模型進行訓(xùn)練�����,同時���,調(diào)用GridSearchCV函數(shù)探索模型的最優(yōu)超參數(shù)組合,采用5折交叉驗證的方式�,以“roc_auc”作為模型評價標準,保存最優(yōu)模型并在測試集上對模型進行評估�。在kernel為最優(yōu)超參數(shù)組合:C=8,gamma=0.01�����。此外���,SVM對HT風險因素進行重要度篩選排序�,排名前10的是:CMB�����、WMH、蛋白尿�、房顫、LHI�����、雙抗治療��、國際標準化比值INR�、紅細胞RBC、TG�����、白細胞WBC���。模型預(yù)測結(jié)果為:精確度為0.71���,準確度為0.70,靈敏度為0.72��,特異度為0.70����,約登指數(shù)為0.42,AUC為0.82���。具體指標見下表5��、圖6����。
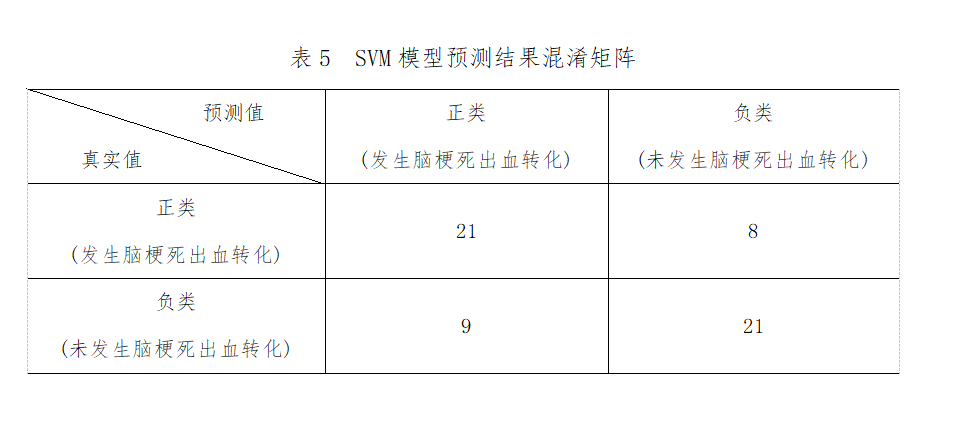
圖6 SVM模型預(yù)測結(jié)果

研究結(jié)果6 各種機器學(xué)習模型結(jié)果比較
五個模型各項指標均顯示良好�,其中RF、AdaBoost�����、XGBoost表現(xiàn)更佳��,精確度�����、準確度�、特異度、靈敏度均在0.97以上����,AUC為0.97 ����,顯示出對HT很好的預(yù)測性能預(yù)測�;單個模型中XGBoost模型的靈敏度最高;AdaBoost和XGBoost模型的AUC最高��。而LR和SVM表現(xiàn)一般��,具體指標見下表6�、圖7
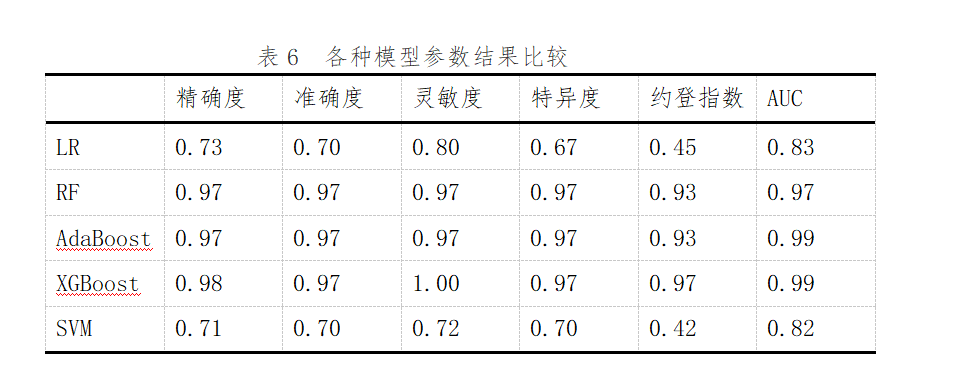
圖7 各種模型結(jié)果比較ROC曲線

研究結(jié)果7 腦梗死后出血轉(zhuǎn)化聯(lián)合預(yù)測模型構(gòu)建結(jié)果
根據(jù)機器學(xué)習算法預(yù)測模型篩選因素結(jié)合專業(yè)方面最終選擇NIHSS、NLR���、雙抗治療、WMH��、LHI���、年齡�、靜脈溶栓�����、CMB�、空腹血糖9項變量進行多因素建模分析���,最終除年齡外8項變量進入模型建立Logistic多因素回歸預(yù)測模型,靈敏度為91.9% 特異度為98.8%����,陽性似然比110.385����,聯(lián)合預(yù)測模型ROC曲線AUC為0.918,P<0.05���。見表7�����、8����,圖8����。
表7 腦梗死后出血轉(zhuǎn)化logistic回歸模型
變量 |
回歸系數(shù) |
標準誤 |
OR值(95%置信區(qū)間) |
P值 |
常量 |
-6.454 |
1.175 |
- |
- |
NIHSS |
0.150 |
0.053 |
1.163(1.047,1.290) |
0.005* |
NLR |
0.164 |
0.074 |
1.178(1.019,1.361) |
0.027* |
雙抗治療 |
1.107 |
0.551 |
3.026(1.028,8.909) |
0.045* |
WMH |
1.680 |
0.673 |
5.363(1.433,20.067) |
0.013* |
LHI |
1.552 |
0.622 |
4.722(1.396,15.977) |
0.041* |
靜脈溶栓 |
1.824 |
0.561 |
6.194(2.064,18.589) |
0.001* |
CMB |
1.647 |
0.625 |
5.193(1.527,17.633) |
0.008* |
空腹血糖 |
0.210 |
0.085 |
1.234(1.045,1.457) |
0.013* |
注:P<0.05為有統(tǒng)計學(xué)差異
表8 ROC曲線下的區(qū)域
檢測項目 |
AUC |
標準誤 |
P |
95%CI |
下限 |
上限 |
Y值 |
0.918 |
0.022 |
<0.001 |
0.875 |
0.961 |
Y值= NIHSS+NLR+雙抗治療+WMH+LHI+靜脈溶栓+CMB+空腹血糖
腦梗死后出血轉(zhuǎn)化多因素風險預(yù)測模型方程為:

X1= NIHSS X2= NLR X3=雙抗治療X4=WMH X5=LHI X6=靜脈溶栓X7=CMB X8=空腹血糖
圖8 HT多因素預(yù)測模型結(jié)果ROC曲線

綜上所述,我們在本研究中對66項變量進行單因素篩選后�����,篩選出年齡、INR��、MWH��、BNP���、CMB等28項變量進入機器學(xué)習模型中���,經(jīng)模型訓(xùn)練驗證后發(fā)現(xiàn)大部分變量均表現(xiàn)良好,機器學(xué)習算法LR���、RF���、AdaBoost、XGBoost及SVM5個模型篩選出年齡���、NIHSS�、靜脈溶栓���、雙抗治療���、WMH���、LHI、CMB��、NLR及空腹血糖為HT獨立危險因素���;在預(yù)測HT方面,LR�、RF、Ada Boost����、XGBoost以及SVM5個機器學(xué)習模型表現(xiàn)均良好,RF�����、AdaBoost�����、XGBoost表現(xiàn)更佳;最后建立的腦梗死出血轉(zhuǎn)化多因素預(yù)測模型同時包含了臨床�、生物學(xué)和影像學(xué)因素,預(yù)測效能方面較其他模型更加全面準確��,對于臨床有很大的指導(dǎo)預(yù)測意義�����。肌鈣蛋白�、BNP、低水平尿酸為HT潛在危險因素�����。
本研究主要研究者為山西醫(yī)科大學(xué)第一臨床醫(yī)學(xué)院博士賈文輝�����,指導(dǎo)教師為李常新教授���,共同研究者為太原理工大學(xué)信息與計算機學(xué)院李鳳蓮教授�、杜鵬����、謝靜��,大連醫(yī)科大學(xué)公共衛(wèi)生學(xué)院雷芳等�。本課題受到國家自然基金合作項目“強化學(xué)習視域下的腦卒中多模態(tài)數(shù)據(jù)集成學(xué)習優(yōu)化算法及發(fā)病風險預(yù)測研究(No.62171307)”和山西省人民醫(yī)院省級專項配套項目基金“腦卒中大數(shù)據(jù)相關(guān)風險預(yù)測模型研究(No.sj20019007)”資助���。

